Meeting 07/11/2019
Participants: Paloma Arillo Aranda, Ana-Maria Babaligea, Vibeke Engesaeth, Cécile Guasch, Thor Moeller, Natalie Muric, Juan Carlos Segura, Jalini Srisgantharajah and Enric Staromiejski.
The meeting of 7th November was focused on the second part of the presentation about how to reuse the FRBR model. The first presentation took place on 22nd October. Both presentations were made by Enric Staromiejski.
The presentation started highlighting the importance of understanding what is meant by the elements “Resource” and “Asset”. Enric came to the WG with two possible definitions for both terms. However, as they were not clear enough the WG worked on a new ones:
-
Resource:
-
Enric’s proposal: a thing, possibly resulting from a work, that is available for its use
-
WG definition: a well identified thing available for use Are you sure the word "thing was in the final definition? What is more I see nothing on resource and asset in the slides Enric sent after the meeting. I know he was writing on the screen do you have a copy of this?
-
Asset:
-
Enric’s proposal: a valuable resource resulting from a work
-
WG definition: a resource resulting from a work possibly bringing value
After the decision of the definitions for Resource and Asset, Enric explained that during the analysis reusing the IFLA LRM specifications 2 challenges were encountered:
-
How the ePO concept of “Document” can be implemented as an “information resource” in contrast to the “bibliographic resource”; and
-
How to implement “a volume resource” that aggregates or collects different “Documents”, e.g. a VCD (Virtual Company Dossier) containing different types of evidences.
Enric explained that in order to reuse the IFLA model new concepts have to be introduced or re-define some of the existing ones. The concepts detected were “Resource”, “Asset”, “Information”, “Document”. The definitions of them have been discussed and new definitions have been created. Note that this concepts have to be represented in the ePO models accordingly:
-
Resource: a well identified thing available for use.
-
Asset: A resource resulting from a work possibly bringing value.
-
Information resource: data, in a context of use. Additional information: in the case of electronic information resources they are accessible via a unique identifier. Why are there 2 IRs there should be only one –
-
Information resource (IR): a set of interrelated data, in a context of use, that is accessible via a unique identifier. Additional Information:
-
The context refers to (source 2009 DAMA International©,
-
The Business meaning of data elements and related terms,
-
The format in which the data is presented,
-
The time-frame represented by the data,
-
The relevance of the data to a given usage,
-
The content retrieved from an information resource is to be considered an “Assset”. Thus, metadata on the provenance, authoring, versioning, etc., is also retrievable/accesible through the information resource.
-
Examples of IRs are “a VCD exchanged via an electronic system”; “a de-referenceable URI returning an electronic certificate on the financial standing of an economic operator”;
-
-
Document: an information resource conveying a set of interrelated business information. Additional Information: examples of Documents within public procurement are: A Contract Notice, an ESPD Request, an electronic certificate such as a certification about the Qualification of an Economic Operator, an eInvoice, etc.
After the creation of the new definitions, and due to not enough remaining time available, Enric explained briefly the rest of the presentation. Enric showed to the WG how the ePO “Information Resource” is implemented:
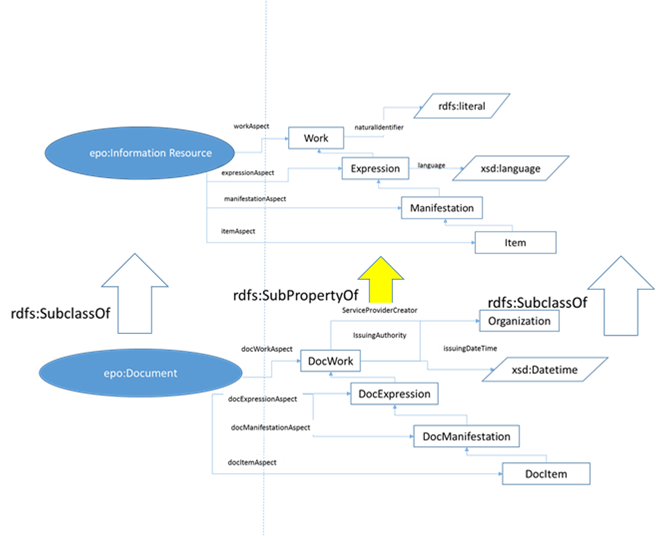
The WG said that this way to represent the concepts is difficult to understand and representing the same concepts and model using our methodology would be better. Everis agreed to do so.
Enric indicated very briefly the “aggregate” element which has to be understood as “a manifestation embodying multiple expressions”, and exist three types of aggregates:
-
Aggregate Collection of Expressions,
-
Aggregates Resulting from Augmentation, and
-
Aggregates of Parallel Expresions.
Enric explained that the modelling of aggregates as a manifestation embodying multiple expressions is simple and straightforward; works and expressions are treated identically regardless of their form of publication or the physical manifestation in which they are embodied. An expression may be published alone or it may be embodied in a manifestation with other expressions.
The next concept explained by Enric are the “serials” modeled by the IFLA LRM. Serials, according to IFLA, are complex constructs that combine whole/part relationships and aggregation relationships.
To finalize the meeting, Enric showed two couples of examples on how to implement collection and how to implement aggregate manifestations in OP’s CDM.