Mapping Methodology
The purpose of this guide is to describe a methodology for creating mapping rules that transform XML data representing the content of the TED “Standard” Forms, into RDF graphs that conform to the eProcurement ontology.
The current mapping methodology relies on resources generated by earlier attempts to create a methodology by e.g., Everis, outcomes of related projects by e.g., by Deloitte e.a., a number of experts in the eProcurement ontology, and Semantic Web technologies in general.
The mappings generated by this methodology are intended for use in the notice transformation workflow for all Tenders Electronic Daily (TED) notices conforming to "Standard" forms that are published in the TED XML format, into RDF format, in order to make them available for querying through a SPARQL endpoint.
Mapping development lifecycle
This section provides a high-level overview of the stage of the mapping development lifecycle just before the mapping suites are ready to be used for transformation in production settings.
The diagram in Figure 1 describes the complete mapping development lifecycle.
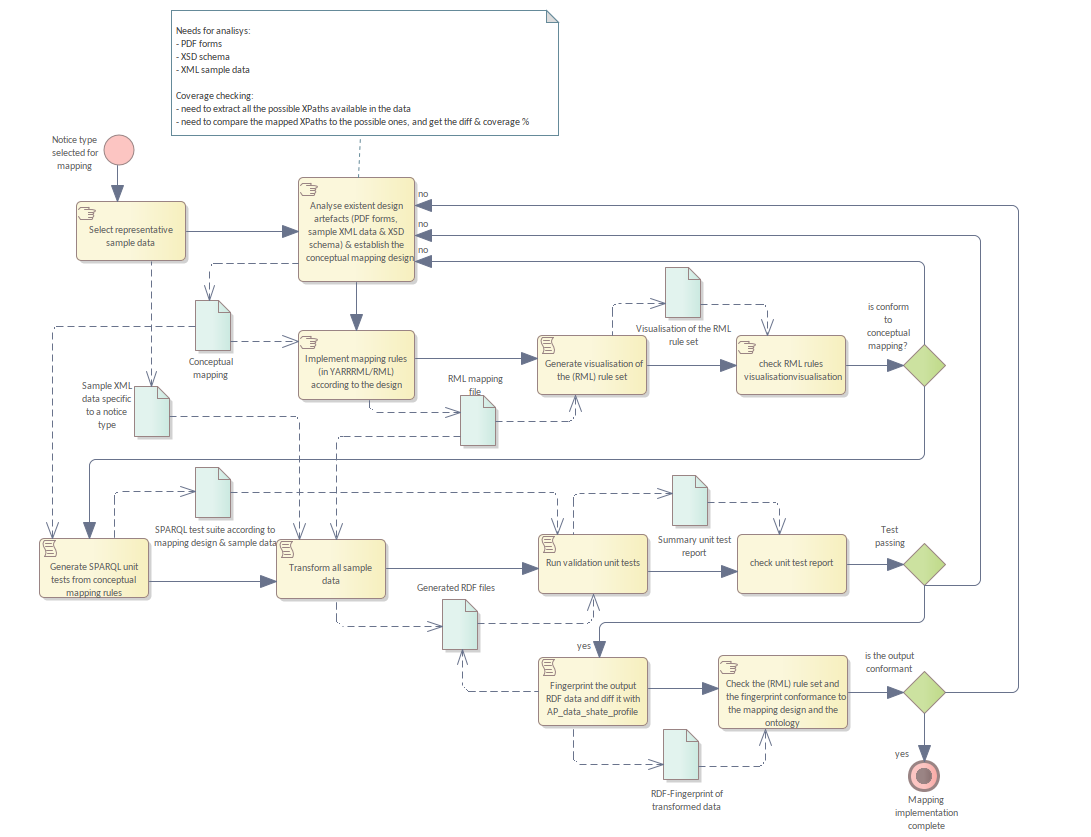
The process starts with the decision of which notice type to map. The notice classification schemes currently targeted are the "standard forms", and the "eForms". New classification schemes will follow in the future.
Once the target form is chosen, a set of representative data is selected which serves as the test set for the mapping.
The notice classification scheme is usually subject to regulations, and described in multiple forms, PDF documents, XSD schemes, and other documents. All possible documentation and modelling artefacts are analysed and used to produce a conceptual mapping (described in the Conceptual mapping structure section). This artefact, stored as a workbook, establishes the correspondence of the TED notice fields to XPath expressions and EPO structures.
Once the conceptual mapping is established between the XPath expressions and ontology structures, a corresponding technical mapping is implemented. This technical mapping consists of a set of mapping rules expressed in RDF Mapping Language (RML), and represents a translation of the conceptual mapping into a formal language which can be executed automatically by a transformation engine such as RMLMapper.
Reading RML for revision or debugging purposes can be difficult. To simplify this process, the RML files can be turned into a more human-friendly HTML report. This detailed document can facilitate e.g., parsing the sets of conceptual and technical mapping rules to check their completeness and/or consistency. This check is a manual step but not the only quality assurance mechanism foreseen in the lifecycle process.
The setup and conventions of the conceptual mapping file permits the generation of several additional artefacts, specifically, a set of SPARQL assertion queries. These queries are used to assess whether the fields mapped in the conceptual mapping are in the same form in the RDF file generated from an XML notice.
To put the SPARQL assertions into practice, sample data is transformed into RDF automatically using the RML mapping rules. The SPARQL queries are then applied to each output resulting in validation reports indicating whether the individual queries generated a positive or negative result. The reports are then analysed for errors in the RML transformation rules or the conceptual mapping.
The final step is the assessment of the generated data: the fingerprinting. This procedure generates a report which reconstructs the data shape instantiated in a particular notice. This facilitates the identification of errors related to the eProcurement ontology.
Key elements involved in the mapping process
This section provides descriptions and references to the key elements (concepts or resources) that are involved in the creation of mappings, or to the mapping process itself.
The purpose of the mapping process is to generate a “mapping table” (described in the conceptual mapping artefact section) that can be processed by the automated workflow of the TED-SWS. The mapping table us used to convert the TED XML input data into an RDF graph (the output of the mapping) that conforms with the eProcurement Ontology. The mapping table is encoded as a spreadsheet containing multiple worksheets.
Notices to be mapped
The inputs for the transformation process are XML files that contain TED notice data. These data are structured according to the “Standard Forms” published by the European Commission. There are 23 standard forms defined (numbered 1-8, 12-25, T1 and T2), whose PDF versions can be found here: https://simap.ted.europa.eu/standard-forms-for-public-procurement.
The XML files must conform to the official Publication Schema.
Over time, different schema have been developed and there is a significant amount of XML data published that conform to the historical versions. The latest XML notices conform to version R2.0.9.S05 of the schema.
Contributing Resources
To create these mappings, a number of resources produced by earlier or concurrent TED projects were used. The following table contains some of these with short descriptions and links to where the resources can be found.
Resource Name |
Description |
The e-Procurement Ontology |
|
TED_EXPORT.xsd |
The XML Schema defined for the TED XML Notices. Download and extract the versions R2.0.9 and R2.0.8 of the TED XML schema from the links named Reception: TED eSenders XML schema on this page: link |
TED forms PDFs |
PDF files representing the physical forms that are to be completed with the relevant data according to each notice. link |
Deloitte & OP - TED_XML_Mapping |
Excel spreadsheets that map elements (fields, sections, etc.) found in the Standard Forms to elements in the eForms. These tables provide the full list of elements and also XPaths to identify the corresponding information TED-XML files. |
Ontology_eForms_NEW_Mapping_New Regulation |
|
Mappings by Everis |
Just for reference. Various parts might be out of date. |
Test data set by Everis |
A set of approx. 300 XML files (6 batches of about 50 files each, for the forms F02, F03, F05, F06, F24 and F25) |
RDF results by Everis |
Just for reference. Various parts might be out of date. |
XML Data analysis |
Contains various tables, each summarising certain aspects (e.g. XML elements related to certain fields in the form) of the data extracted from test notice files. |
XML Elements to Vocabulary Mapping |
|
TED Mappings to ePO terms |
|
conventions_report.html |
Transformation output
The output of the XML notice transformation is an RDF graph instantiating the eProcurement Ontology, containing a number of RDF triples where the subjects, predicates and objects of the triples are either:
-
unique Internationalized Resource Identifiers (IRIs) that can identify the notice or the different component parts of a notice. These IRIs (or sometimes blank nodes) are used in multiple triples as subjects OR objects to build an RDF graph;
-
IRIs representing controlled vocabulary terms or entities in the ePO ontology;
-
Literals representing numbers, boolean values, or strings. The string values are often encoded as multilingual strings of type rdf:langString., to facilitate the representation of textual values in multiple European languages.
Mapping files produced
The key element enabling transformation automation are the mapping files: conceptual and technical mappings that are developed according to the mapping creation methodology.
The mapping rules are organised in mapping suites, described in the Mapping Suite Structure.
Conceptual mapping structure
This section describes the structure of the mapping file created as a result of the described mapping process. The mapping file is an Excel workbook containing multiple worksheets. This workbook is generated from a Google Sheets document, where it can be prepared, revised, and refined by multiple contributors in a collaborative fashion. This template informs software developers and knowledge engineers of the mapping file content.
It consists of several worksheets:
-
Metadata sheet: provides technical and descriptive information about the mapping suite.
-
Resources sheet: provides the list of resources used in the technical mappings. This list is used to populate the mapping suite with indicated resources files automatically.
-
Rules sheet: provides the actual set of mapping rules.
-
Misc: there are optional worksheets added by semantic engineers to manage additional information.
The Metadata sheet
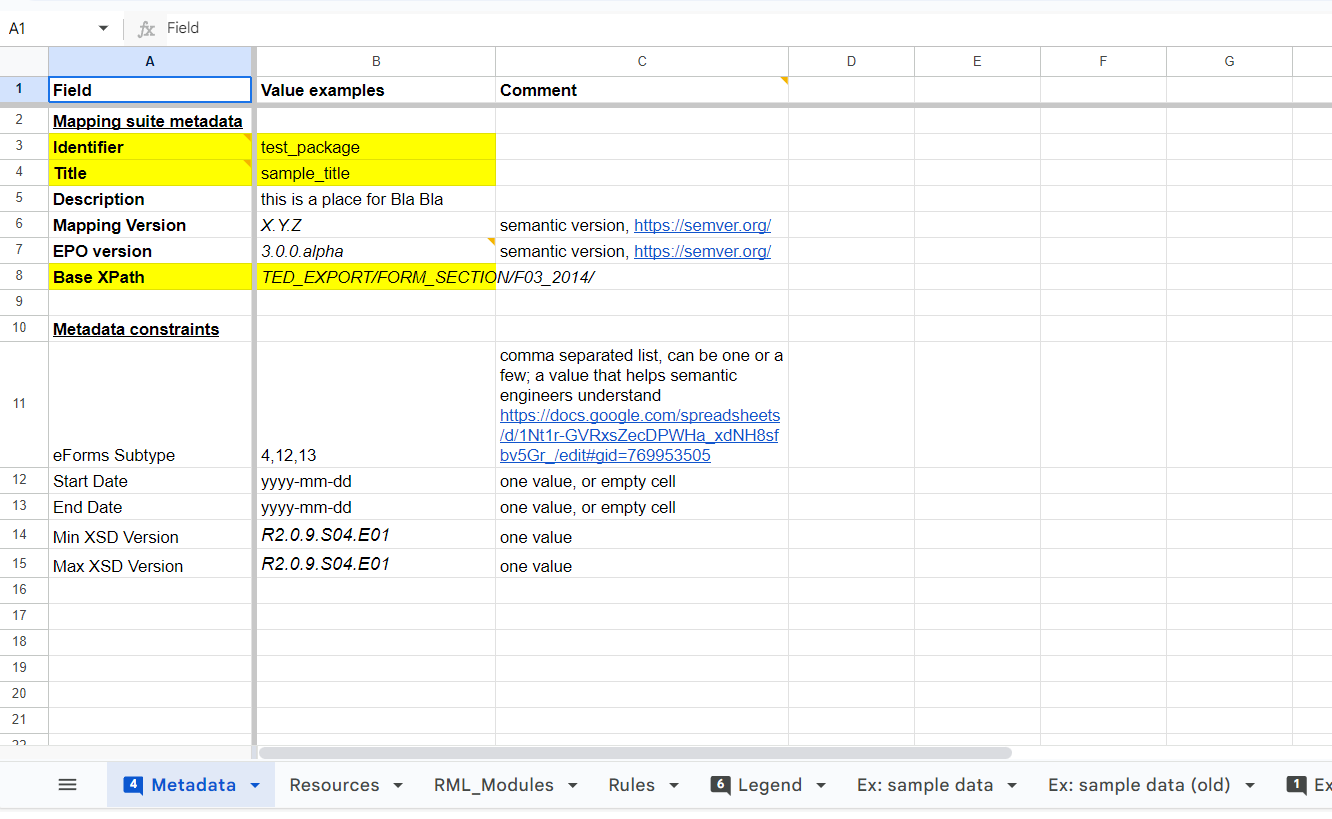
| Cell refs. | Header for content | Description | Notes |
|---|---|---|---|
B2 |
Form number |
Standard Form number (one of F03-F08, F12-F25, T1 or T2). For multiple forms a comma separated list can be used. |
See list of standard forms here |
B3 |
Legal Basis |
Filter for the directives that constitute the legal bases for the notice. For multiple directives a comma separated list can be used. For any value the character * can be used. |
Examples: D24 / D23, D25 / R1370 |
B4 |
Year |
Filter for the year when the notice was published. For multiple years a comma separated list or ranges of the form startYear-endYear, or a combination of these two can be used. For any value the character * can be used. |
Valid examples: 2018 / 2016-2020 / 2016, 2018-2020 |
B5 |
Notice type (eForms) |
[TODO] |
|
B6 |
Form type (eForms) |
[TODO] |
|
B7 |
Mapping Version |
A version number for the current mapping table. The version number should be increased for each “released” version of the mapping table that is different from the previously released version, following semantic versioning practices. |
Example values: 0.1.0 / 1.0.0-beta / 1.1.0 / 2.3.2 |
B8 |
EPO version |
The version number of EPO to which the mapping is done. |
|
B9 |
XSD version number(s) |
The version number of the TED XML Schema file. Ranges should be also allowed. For multiple versions a comma separated list or ranges of the form (startVersion, endVersion), or a combination of these two can be used. For any value the character * can be used. |
Example values: R2.0.9.S05 (this includes all intermediary versions of R2.0.9.S05.E01, such as R2.0.9.S05.E01_001-20210730) / R2.0.9.S04.E01_002-20201027, R2.0.9.S04.E01_001-20201008 / (R2.0.9.S03.E01_005-20180515, R2.0.9.S03.E01_010-20200224] / Theoretically anything like this could be used: (,1.0],[1.2,) |
The Resources sheet
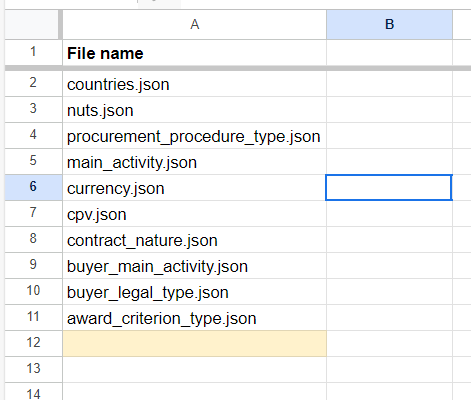
| Cell refs. | Header for content | Description | Notes |
|---|---|---|---|
A2:A |
File name |
The name of the resource files that are used by the mappings and need to be present in the +resources +folder. |
|
The Rules sheet

Cell refs. |
Header for content |
Description |
Notes |
A:D |
Conceptual mapping |
||
A3:A |
Standard Form Field ID (M) |
The “identifier” of the field in the Standard Form PDF file. Usually the field number, such as IV.1.1.1.2, or the section name, e.g. “Section IV” |
Mandatory |
B3:B |
Standard Form Field Name (M) |
The name of the field in the Standard Form PDF |
Mandatory |
C3:C |
eForm BT-ID (O) |
The ID of the corresponding business term (BT) or business term group (BG) in eForms. The values are coming from the column B of this spreadsheet (or one of its equivalents): |
Optional |
D3:D |
eForm BT Name (O) |
The name of the corresponding business term (BT) or business term group (BG) in eForms. The values are coming from the column C of this spreadsheet (or one of its equivalents): |
Optional |
E:F |
Standard form technical mapping |
||
E3:E |
Base XPath (for anchoring) (M) |
The “base” XPath that identifies an XML element and all of its sub-elements. It can be specified at the level of a section, or subsection, so that writing XPaths for form elements within that (sub)section will not have to repeat over and over again the “base” XPath. |
Mandatory |
F3:F |
Field XPath (M) |
The XPath that identifies the form element, which is relative to the “base” XPath that was specified for the closest element above this one. |
Mandatory |
G:J |
ePO mapping |
||
G3:G |
Class path (M) |
Specifies the types of the resources involved in the entire “path” from the subject to the object, which “connects” the concept that represents this XML element (the object), to an RDF resource already created from previous XML elements (the subject). So, if the representation of an XML element involves the creation of the following triples: s p1 o1. o1 p2 o2. o2 p3 o. |
Mandatory |
H3:H |
Property path (M) |
Specifies the properties involved in the entire “path” from the subject to the object, which “connects” the concept that represents this XML element (the object), to an RDF resource already created from previous XML elements (the subject). So, if the representation of an XML element involves the creation of the following triples: s p1 o1. o1 p2 o2. o2 p3 o. |
Mandatory |
I3:I |
Triple fingerprint (O) |
[TODO] |
Optional |
J3:J |
Fragment fingerprint (O) |
[TODO] |
Optional |
Mapping development methodology
This section gives a high-level overview of the process for creating the mapping rules for transforming XML TED notices into RDF triples that use ePO terms.
The methodology described focuses on the steps and artefacts at the core of Figure 2. This diagram shows a subsection of the mapping lifecycle.
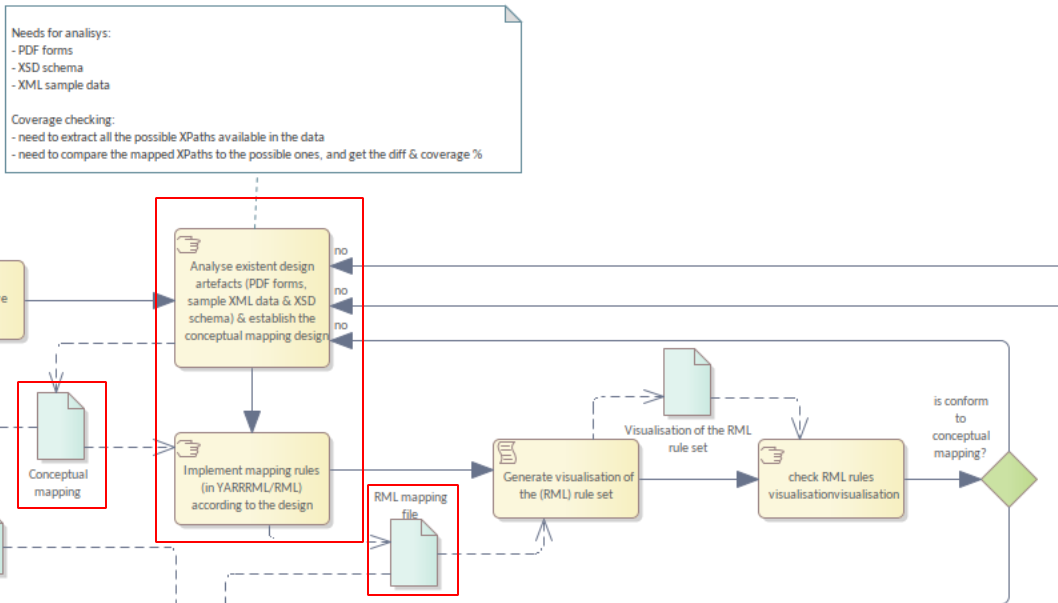
Following the theoretical framework, and learning from the manual creation of mappings, the mapping creation process has been enhanced and refined.
The focus here is on describing the steps by which the conceptual mapping and the technical mapping are created.
Creation of conceptual mappings:
-
The identification of the form elements (and the corresponding XML elements and XPaths) to be mapped
-
The identification of the eForm Business Terms (BT) corresponding to the XML elements (optional)
-
The identification of the ePO terms (classes and relations) that correspond to XML elements and their relationships
-
The identification of the value sets in XML
-
The identification of the value sets in ePO, and in other vocabularies corresponding to XML controlled values used in the XML files
-
Writing Turtle fragments that provide a template for the triples that should be generated, and which can be used in the RML mapping rules
-
The identification and documentation of problems/issue/questions that are to be clarified with external experts
Creation of technical mappings:
-
The identification of the sources that are necessary to execute a mapping
-
The preparation of vocabulary files, and other “dictionaries” that are to be used as resources for the mapping
-
The preparation of test data
-
Writing YARRRML rules (optional)
-
Writing RML rules (or convert YARRRML rules to RML) and test them
-
Documenting problems and creating (Helpdesk)tasks to find solutions for them
Testing the mapping in various ways to discover potential problems and improvments:
-
Running the mapping on all test notices files and analysing the output
-
Generating the various validation outputs (SHACL shapes, SPARQL queries etc.), for all test data and analyse it
-
Executing any other steps in the mapping development lifecycle to find potential issues and refine the mapping
Next, a more detailed description of the necessary steps in the conceptual mapping process is provided.
Steps involved in the conceptual mapping process
The conceptual mapping is the first artefact that must be created. It requires a thorough understanding of the content of a form (standard or eForm), and all the related concepts in the ePO ontology. It will most likely involve rounds of discussions with subject experts. Below, some of the sub-steps involved in developing the conceptual mapping are described.
Identification of the Form Elements (and the Corresponding XML Elements and XPaths) that are to be mapped
The identification of the the XML elements that contain information to be mapped to RDF requires that the following are examined:
-
The “Standard Forms to eForms” mapping table that corresponds to the form that is to be mapped is used. This provides both the list of the form elements, and XPath expressions that can be used to retrieve the desired information: XML elements, attributes, etc, from the XML data.
| XPaths can be straight forward or complex. Multiple XPaths are used to retrieve alternative values. These XPaths need to be tested to establish whether simpler, better and/or more appropriate ones can be written. |
-
The TED_EXPORT.xsd schema file, corresponding to the XML version to be mapped.
| Special attention should be paid to the structure of the XML document (especially when we have repeating elements, or multiple levels of nesting, sometimes involving elements with very similar names) |
-
The PDF form being mapped, to make sure that all elements are considered vered and the correct semantic of the fields has been identified.
-
Individual XML notices available in the test data set, as well as data extracted from these and compiled in tables to provide an overview of the different values contained in test data fields.
The Identification of eForm Business Terms (BT) corresponding to the XML elements (optional)
Although this is not necessary for the conversion of the Standard Form XML to RDF data, it is still useful, from a future-oriented perspective, to identify the eForm Business Terms corresponding to each Standard Form element. This is relatively straight forward using the “Standard Forms to eForms” mapping table.
The Identification of ePO terms (classes and relations) that correspond to XML elements and their relationships
In this step, the relevant classes, class attributes, and relationships between the ePO classes used to represent the information contained in the XML elements is identified. This requires a deep understanding of the ePO model.
Identifying the relevant ePO terms may be complex, as there is a significant difference between the conceptualisations and abstractions made in the two models, and also in the names used for the same concept between models. Consultion with subject matter experts regarding the structure and content of the ePO model, is highly recommended.
Any problems or discrepancies discovered, that prevent the creation of a perfect (one-to-one) mapping, should be documented. This should be recorded both on the spreadsheet (e.g. by highlighting problematic cells in certain colours and/or adding comments to them), and by describing issues in a separate document that is reviewed and addressed by ePO experts.
The Identification of value sets in XML
To identify the value sets (i.e. the possible different values) that are used in the XML data, either as certain element names, or attribute values), the following are examined:
-
The TED_EXPORT.xsd schema file, corresponding to the XML version being mapped,
-
The values that appear in the sample XML notices.
-
The PDF form that is being mapped, to establish whether the form specifies an obvious value set, e.g. by means of checkboxes or radio buttons.
-
The authority tables used in the EPO available from the EU Vocabularies
The Identification of value sets in the ePO and other vocabularies corresponding to XML controlled values used in the XML files
In this step the identification of the different vocabularies referenced by ePO attributes and relationships involved in the mapping of a certain XML element is done. A familiarity with the vocabulary should be achieved. At a minimum, what namespace is used, what some of their values are, and how are they encoded should be understood (i.e. which properties they are using to encode labels, ids, etc).
Writing Turtle fragments that provide a template for the triples to be generated, that are used in the RML mapping rules
Below is an example of an input (XML notice’s fragment), and it’s transformation (RDF result) of an organisation definition.
XML fragment (source.xml)
<TED_EXPORT>
<FORM_SECTION>
<F03_2014 CATEGORY="ORIGINAL" FORM="F03" LG="PT">
<CONTRACTING_BODY>
<ADDRESS_CONTRACTING_BODY>
<OFFICIALNAME>Administração Regional de Saúde do Alentejo, I. P.</OFFICIALNAME>
<ADDRESS_CONTRACTING_BODY>
<CONTRACTING_BODY>
<F03_2014 CATEGORY="ORIGINAL" FORM="F03" LG="PT">
<FORM_SECTION>
<TED_EXPORT>
Expected RDF result (result.ttl)
@prefix org: <http://www.w3.org/ns/org#> .
@prefix epo: <http://data.europa.eu/a4g/ontology#> .
epo:Organization/2021-S-001-000163/ab152979-15bf-30c3-b6f3-e0c554cfa9d0
a org:Organization;
epo:hasName "Administração Regional de Saúde do Alentejo, I. P."@pt .
The corresponding RML rules to do such a transformation are in the section: Writing RML rules.
Identifying and documenting problems/issue/questions requiring consultation with external experts
The way RML rules are written (see technical mapping chapter) is in a TripleMap.
Each one contains:
-
"LogicalSource" that gives information about the source (XML file to transform)
-
"referenceFormulation" which is the language used to parse the source.
An up to date version of RML Mapper that supports XPath 2.0/3.0 is used which supports the default namespaces.
The steps involved in the technical mapping process
This section describes what needs to be addressed in the technical mapping step of the mapping creation process.
The identification of the necessary sources for mapping execution
All necessary sources must be defined correctly in the YARRRML/RML files, and refer to files that already exist, or that will be available in the mapping package when running the mapping.
The path to the source files should be specified relative to the RML file(s) e.g., if the RML mapping files are in the transformation/mappings folder (as described above), then the sources they define should point to the ../../data/data.xml file, respectively to the various .json, .csv and/or .xml files in the ./resources folder
|
Preparing test data
The representative sample data selection chapter should be referred to.
Writing YARRRML Rules (optional)
During the initial phase of the mapping creation process, the writing of the mapping rules in YARRRML (a human-readable text-based representation for declarative generation rules), instead of RML took place, because it seemed simpler, and the end result was more human friendly. However, as more experience and confidence in how the mappings should be defined was gained, it was realised that writing RML rules directly could be even more powerful, and the project started to rewrite all the YARRRML mapping rules into RML. If this transition proves to be successful, and writing RML rules directly will be more convenient, our process will not require writing YARRRML rules in the future. This is the reason for why this step is optional. It could be useful for small test cases, quick demos, or showcases, and in cases when some people are more familiar with YARRRML than RML. If people decide to write YARRRML rules, the next step will become unnecessary, as the RML rules will be automatically generated from the YARRRML rules, using dedicated tools that were developed for this purpose.
Since this step is optional, the individual issues that need to be worked on will not be described in detail , but they are in principle the same as the ones described in the next section.
Writing RML rules
In the previous step the mapping rules were defined in YARRRML. This step consists of the simple action of executing the tool that generates RML out of YARRRML.
Regardless of which file is chosen to be defined manually, YARRRML or RML, the goal of this step is to have an RML mapping file that should be able to convert an XML notice into a corresponding RDF graph.
In the rest of this section the assumption is made that the RML rules are being written manually, as this is the solution that offers the greatest potential benefit, and the approach that is likely to be pursued in the future.
The technical mappings are written in the RML mapping language. The version of RML used is 5.0.0-r362, which was recommended to us by Julian Rojas, its principal developer, in which XPath version 3.1 is supported.
Prefix definition
To specify the technical mappings in RML, the definition of the prefixes that are used in the mapping file must be defined first. For example for the ePO ontology, the epo prefix name is defined as follows:
@prefix epo: <http://data.europa.eu/a4g/ontology#> .
The prefix names and their values, which are used in the RML file, should ALL be maintained in the prefixes.json resource file. If the content of that file is maintained and kept up to date consistently, the entire prefix declaration section of the RML file could be automatically generated, and re-generated when necessary. (Note: Besides the individual prefixes, the array that is the assigned value to the rml_rules key should be viewed).
TriplesMap
After the definition of prefixes, the next step is to define the various TriplesMaps for the creation of class instances. For example, an organisation’s technical mapping:
<#OrganisationMapping> a rr:TriplesMap ;
rml:logicalSource
[
rml:source "source.xml" ;
rml:referenceFormulation ql:XPath
rml:iterator "/TED_EXPORT/FORM_SECTION/F03_2014/CONTRACTING_BODY/ADDRESS_CONTRACTING_BODY" ;
] ;
The TriplesMap of this organisation is called “OrganisationMapping”. This name is a unique reference used to generate the rdf dataset, and to refer to it in other mappings.
A TripleMap has:
-
rml:logicalSource: containing the source (it can be the xml notice that is being transformied, or a CSV/JSON file containing the controlled values) -
rml:referenceFormulation: defining the parser for the file. In the case of the XML notices XPath is used, while for the CSV/JSON files it isql:CSV/ql:JsonPath -
rml:iterator: the path were the RML mapping starts iterating for this Organisation Mapping.
SubjectMap
The subjectMap describes how to generate a unique subject value of a TriplesMap (e.g. Organisation).
rr:subjectMap
[
rr:template
"http://data.europa.eu/a4g/resource/Organisation/{replace(replace(/TED_EXPORT/CODED_DATA_SECTION/NOTICE_DATA/NO_DOC_OJS, ' ', '-' ), '/' , '-')}/{substring-before(substring-after(unparsed-text('https://www.uuidtools.com/api/generate/v3/namespace/ns:url/name/' || count(preceding::*)+1),'[\"'),'\"]')}" ;
rr:class org:Organization
] ;
The subject should be unique to each different organisation found in an XML notice. To do that, a concatenation of
-
a cleaned reference of the notice file
replace(replace(/TED_EXPORT/CODED_DATA_SECTION/NOTICE_DATA/NO_DOC_OJS, ' ', '-' ), '/' , '-'); and -
a cleaned result of a
MD5function which returns a UUID based on the position of the iterator that is unique to each organisation on the XML notice is used. This is done withsubstring-before(substring-after(unparsed-text('https://www.uuidtools.com/api/generate/v3/namespace/ns:url/name/' || count(preceding::*)+1),'[\"'),'\"]'); -
the type of the mapping is defined by rr:class org:Organization
This solution also helps us to handle having nested tags, by giving each of them a different uuid via the result of the position XPath function.
predicateObjectMap
A nested set of predicates objects map to each predicate/object of the organisation instance.
rr:predicateObjectMap
[
rr:predicate epo:hasName ;
rr:objectMap
[
rml:reference "OFFICIALNAME"
]
] ;
In this part of a TriplesMap we find two components:
-
A predicate
rr:predicate epo:hasName; -
An objectMap, which can be either
-
a rml:reference which is the XPath (starting from the iterator) into the XML notice corresponding to the value of the predicate (OFFICIALNAME), or
-
a rml:template that contains a combination of string and XPath expression
-
Referenceingo other mappings
A referencing object map allows using the subjects of another Triplesmap as the objects generated by a predicate-object map.
There are two use cases for connecting two TriplesMaps using the rr:parentTriplesMap pattern
-
A referencing object map is represented by a resource that has exactly one
rr:parentTriplesMapproperty (without joint condition). Here is an example of connecting the Organisation to its ContactPoint
rr:predicateObjectMap
[
rr:predicate epo:hasDefaultContactPoint ;
rr:objectMap
[
rr:parentTriplesMap <#ContactPoint>
] ;
] ;
-
A referencing object map is represented by a resource that has many
rr:parentTriplesMapproperties (we use arr:joinCondition). Below is an example of connecting an Address to its NUTS code:
rr:predicateObjectMap
[
rr:predicate locn:adminUnitL1 ;
rr:objectMap
[
rr:parentTriplesMap <#nuts>;
rr:joinCondition [
rr:child "*:NUTS/@CODE";
rr:parent "code.value";
];
] ;
] ;
A join condition is represented by a resource that has exactly one value for each of the following two properties:
-
rr:child, whose value is known as the join condition’s child reference (the path into the Address TriplesMap) -
rr:parent, whose value is known as the join condition’s parent source (the path into the ContactPont TriplesMap))
Document technical and philosophical issues
While writing the mapping rules, it is necessary to document any issues that are not solvable, or that raise interesting questions. If warranted, a Jira task should be also created to address the given issue.
Problems that were successfully resolved should be integrated into this guide as recommendations. Deleting the issue from the “Problem description” document is NOT recommended, so that the different issues can be kept track of, and that thinking process that went into choosing the ultimate solution(s) is recorded.
Create RML Rules Modules
Forms tend to have similar or identical sections i.e., represent the same information. For example form F03 and F06 have the same section 1, which is the information about the contract authority.
To remove the need to write transformation rules twice (for section 1 of F03 and section 1 of F06), a module system has been set up which consists of writing transformation rules that are reusable by several forms. This has the following advantages:
-
Not needing to rewrite the same rules several times for different forms (avoiding duplication of rules).
-
When updating the ePO ontology, the modification will only need to be updated once and will then be passed to all the affected forms.
As explained in the technical mapping creation section, a TripleMap represents a mapping of an XML element and its content with one class in the ontology, and a set of its predicates objects. To have a module that can be reused on many forms, only the predicates objects of a TripleMap are defined in the module files. The logical sources and subjects map, needed in every TripleMap object, are described separately in the main file as they contain information specific to every form, making these parts of the TripleMap object non-reusable. For example a module that contain an organisation looked like that:
<#OrganisationMapping> a rr:TriplesMap ; rr:predicateObjectMap [ rr:predicate epo:hasName ; rr:objectMap [ rml:reference "OFFICIALNAME" ] ] ;
This module is extended in the main file of F03 by adding the logicalSource and the SubjectMap in this way:
<#OrganisationMapping> a rr:TriplesMap ; rml:logicalSource [ rml:source "source.xml" ; rml:referenceFormulation ql:XPath rml:iterator "/TED_EXPORT/FORM_SECTION/F03_2014/CONTRACTING_BODY/ADDRESS_CONTRACTING_BODY" ; ] ; rr:subjectMap [ rr:template "http://data.europa.eu/a4g/resource/Organisation/uuid_generation_function ; rr:class epo:Organisation ] ;
The modules are stored in the ted-rdf-mapping project in the src/mappings folder.
Five modules that represent the five sections of F03 and part of F06/F25, and one for Annex D1, which is part of F03 are covered. These are:
-
s1_contracting_authority.rml.ttl
-
s2_object.rml.ttl
-
s4_procedure.rml.ttl
-
s5_award_of_contract.rml.ttl
-
s6_complementary_information.rml.ttl
-
annex_d1.rml.ttl
The project contains one src/mappings folder containing all the modules files and one "main" entry point mapping file for each form package. Here is a representation:
/ted-rdf-mapping /XXX /mappings /package_F03 /transformation XXXX /mappings ... technical_mapping_F03.rml.ttl /package_FXX /transformation XXXX /mappings ... technical_mapping_FXX.rml.ttl /src /mappings annex_d1.rml.ttl s1_contracting_authority.rml.ttl s2_object.rml.ttl s4_procedure.rml.ttl s5_award_of_contract.rml.ttl s6_complementary_information.rml.ttl technical_mapping_F03.rml.ttl technical_mapping_FXX.rml.ttl
Any comments on the documentation?